Jan. 2013 - von Gert Redlich - Gedanken zur automatischen Erstellung aussagekräftiger Schlagwort- bzw. Indexdateien zur Unterstützung des Suche in großen Textmengen:

- Beispiel hifimuseum.de
Aktueller Zustand :
Ich habe 4 Museumsseiten - Fernsehmuseum - Hifimuseum - Tonbandmuseum. Und seit einem Jahr ist die Content-Menge insgesamt so groß und umfangreich, daß sich Besucher oder Gäste reichlich überfordert vorkommen. (mehrere Telefonate) Die Museums-Seiten haben inzwischen mehr als 12.000 Bildschirmseiten und die Inhaltsverzeichnissse sind sehr sehr lang und damit nicht mehr besonders hilfreich, eher verwirrend.
Die erste mögliche Hilfe:
Ein Inhaltsverzeichnis - Doch selbst mit den besten Inhaltsverzeichnissen ist dem Surfer nicht mehr geholfen, wenn er gar nicht mehr weiß, wonach er suchen sollte oder könnte.
Theoretische Perspektive:
Dafür gäbe es die sogenannten Glossars oder Glossarys, auch Schlagwort- Verzeichnisse genannt. Das sind die auf der jeweiligen Site bzw. auf den Seiten vorkommenden Schlagwörter (zum Nachschlagen), die für die dort behandelten Themen von Relevanz sind.
Grenzen der händischen Methoden:
Doch auch die Menge dieser Schlagworte ufert aus (bei mir 74.000), wenn mal genügend Text=Content drinnen ist. In den Typo3 Glossar-Extensions heißt es dann, man möge diese Schlagworte "einfach mal" von Hand eintragen.
Eine hoffnungslose Aufgabe:
Doch diese Arbeit würde bei mir Nächte füllen. Das ist (zeitlich) unzumutbar, denn es müsste in periodischen Abständen erneuert werden. Fazit: Es müsste also irgendwie automatisiert werden können.
Ich brauche 2 Ergebnislisten:
- Die Such-Liste für die Site spezifische Suche = Meine Suchmaschine sucht sowieso nur nach den vorhandenen Wörtern in der mnogosearch Tabelle wordcount. Dort sollten nur noch 20.00 bis 30.000 Wörter (von derzeit 74.000) stehen.
- Die Such-Wort-"Vorschlags"-liste zum Import in ein Glossar mit ca 1.000 Such-Wort-Vorschlägen.
.
In den großen aktuellen Suchmaschinen ist die "Stemming" Methode (Ergänzung der realen Schlagwörter durch Synonyme) seit einiger Zeit integriert. Also auch ungenaue bzw. näherungsweise Anfragen werden ergänzt / korrigiert und bei den Ergebnislisten aufgeführt.
.
- Export nur der (Hifimuseum.de) tt_content Tabelle (8.500 Records) mit phpmyadmin in eine CSV Datei (um nicht erforderliche Spalten mit Excel zu löschen)
- Die Datei testen auf korrekte deutsche Umlaute, (öffnen mit Windows Notepad und gleich wieder als utf8 abspeichern)
- Dann Löschen aller nicht benötigten Spalten bis die Suchwort-Spalte (mit den Header, Body und Image-Texten)
- Alles exportieren in eine große Textdatei und dann kommt das große Staunen. Da steht ja ungeheuer viel Mist drinnen. Da ist Filtern angesagt.
.
Also so geht es nicht, auch nicht mit einem der wenigen Programme zum Extrahieren von Phrasen unter Zuhilfenahme von "stoplists". Es ist sehr mühsam, selbst mit einer "stoplist" bzw. einer "blacklist" für unerwünschte Wörter - sowie mit einer Begrenzung auf mindestens 4 Buchstaben sowie Ausschluß von Wörtern, die mit einer Zahl beginnen. Das Progamm "extphr33.exe" ist zwar ein große Hilfe, mal die Wort-Mengen abzuschätzen, doch das ist alles viel zu aufwendig und vor allem - nicht zu automatisieren.
Die mnoGoSearch Engine setzt direkt auf der Linux System-Ebene und auf mysql auf - und indiziert meinen Typo3 Content (jede Nacht per cron-job). Am Beispiel des Inhaltes der Webseiten von www.hifimuseum.de habe ich mich an der automatisch generierten Wortliste versucht. Die hifimuseum Content Tabelle tt_content enthält deutlich über 10.000 Datensätze mit ca. 14 Megabyte reinem Text.
Wenn der "mnoGoSearch Indexer" (einmal in der Nacht) gelaufen ist, stehen in der allerletzten Tabelle mit den Word-Counts ca. 78.500 eindeutig indizierte Einträge aller im gesamten Text vorkommenden "Wörter" (besser "strings"), wobei jedes Wort in dieser Tabelle wirklich nur einmal enthalten ist. In einem anderen Feld steht auch noch die Anzahl der Vorkommnisse jedes einzelnen Wortes. Diese Spalte lösche aber ich später, weil sie für mich überhaupt keine Relevanz hat.
.
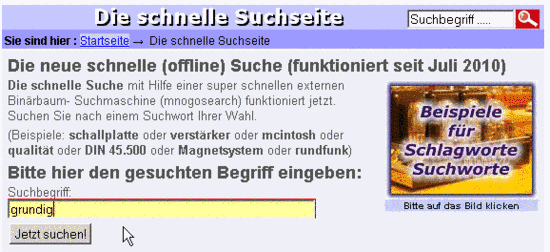
- Gesucht wird nach "Grundig" - eingetippt wird aber klein - zum Vergrössern bitte klicken
Es ist logisch verständlich, daß der mnogosearch Indexer alle gefundenen und erlaubten Wörter komplett in Kleinbuchstaben konvertiert. Denn so gut wie jede Suche wird mit Kleinbuchstaben (in das jeweilige Suchfenster) eingetippt.
Das ist zwar für das eigentliche Suchen ok, doch für meinen Zweck einer Schlagwort-Vorschlagliste unglücklich. In diesem Suchwort-Vorschlags Glossar hätte ich gerne die Substantive wie gewohnt mit großem Anfangsbuchstaben. Verben und Attribute wollte ich sowieso ausschließen und auch nur 4stellige Jahreszahlen akzeptieren.
So muß vermutlich die Indexer-Source Datei angepaßt werden, um in der wordcount-Tabelle (in einem weiteren Feld) den gleichen Schlagworteintrag noch einmal "im nicht konvertierten" Original-String zu speichern.
.
Wenn ich also bei der normalen (automatischen offline) Indizierung der mnogosearch Engine die zur Zeit genutzte "stoplist (1)" mit den deutschen und englischen (auszuschließenden) Wörtern oder Fragmenten auffülle, die auch bei der normalen Suche ganz bestimmt nicht gebraucht werden, dann reduziere ich die jetzt 74.500 Ergebnisse in der Ergebnis-Liste (1) auf nur noch ca. 20.000 oder nur noch 15.000 Ergebnisse in dieser mysql wordcount Tabelle.
Das sind aber immer noch zu viele für ein vernünftiges verständliches (Suchwort-) "Vorschlagewesen", unser zukünftiges Glossar.
Nehme ich also in der zweiten Stufe die aus der wordcount Tabelle exportierte Ergebnis-Liste (1) und filtere den Text nochmal mit einer zweiten "stoplist (2)" auf etwa 1.000 alphabetische Begriffe (bei mir aus dem Museumsbereich), sollten am Ende in der Ergebnis-Liste (2) etwa 1.200 Schlagwörter (Jahreszahlen sind auch Schlagwörter) samt der Eigennamen der Hersteller und Erfinder und sonstiger Beteiligter übrig bleiben. Soweit die Theorie.
.
Das bedeutet zuerst: Die "stoplist(1)" der serverseitigen mnoGosSarch Engine muß soweit aufgefüllt werden, daß nur noch vernünftige Suchwörter überhaupt für die Eingabe von Hand in das Suchfeld zur Verfügung stehen.
Aus der resultierenden wordcount Liste müssen alle nicht gewünschten Zeichenketten aller Art (vermutlich an die 9.000 "unsinnige" Wörter) in die "stoplist(2)" eingetragen werden, die mit einem Stream Filter die zukünftige Schlagwort-Vorschlagdatei auf ca. 1.000 Einträge zusammenschrumpft.
Sinnvollerweise sollte diese Schlagwort-Vorschlagdatei vor dem Import in das finale Glossar mit weiteren ausgewählten Synonymen aufgefüllt werden, die sich aus den Schlagwörtern (von Hand mit dem Kopf) herleiten lassen. Das muß sicher händisch gemacht werden, jedoch jeweils nur als update.
Es gibt mehrere Typo3 Glossar-Extensions, die ein Import von vorbereiteten Glossarys aus Textdateien in die Glossary-Tabelle(n) ermöglichen und eine sehr angenehme und handliche nach Buchstaben gelistete Web-Oberfläche bereitstellen.
Eine wünschenswerte Zusatzfunktion läge natürlich auf der Hand: Wenn man dort im Glossar eines dieser Schlagworte anklickt, sollte sofort die schnelle Suche starten und die Fundstellen würden in Bruchteilen von Sekunden angezeigt.
Das wäre also die optimale Hilfestellung für den verwirrten Besucher / Gast / Surfer - jedenfalls stell ich mir das so vor.
.
.
- Die (vom Indexer) aufgerufene Stoplist(1).txt wird bei Bedarf von Hand mit den jeweils neuen aktuell auszuschließenden Wörtern ergänzt (oder auch so belassen)
- Diese (jetzt modifizierte) Stoplist(1).txt wird wieder in eine eindeutig indizierte mysql Tabelle (mit nur einem Textfeld) eingelesen, um eventuelle neu hinzugekommene Duplikate zu entfernen.
- Dann wird diese bereinigte Stoplist(1) wieder rausgeschrieben - dabei direkt in die von mnogosearch zu ladende Stoplist1 Vorlage namens "en.huge.sl .
- Nach erfolgtem Indexer Lauf wird von der (jetzt gefüllten) Tabelle Nr. 250 (wrdstat) das Feld "word" (oder das eventuell neue Feld "word2") in eine Glossar Vorlage-Textdatei exportiert.
- Mit Hilfe eines Filterprogrammes wird die Stoplist(2) über die Glossar Vorlage laufen lassen und die Glossar Vorlage auf maximal 1.000 fachlich sinnvolle Schlagwörter reduziert.
- Dann wird die (von Hand erstellte und gepflegte) Synonym-Vorlage Datei zu der Glossar Vorlage hinzugefügt.
- Als letzer Vorgang wird die optimierte "Schlagwort-mit-Synonym"- Vorlage in die Typo3 Glossar Extension importiert.
.
.
- Je Museums-Site werden (zur Zeit) etwa 1 Million Wörter verarbeitet, von denen aber nur etwa sinnvolle 20.000 bis 40.000 in dieser mnogosearch "wrdstat"- Datei enthalten sein sollten.
- Wörter, die nicht in der "wrdstat" Tabelle enthalten sind, können bei der mngosearch nämlich gar nicht gesucht und damit gefunden werden, bzw. führen zum sofortigen Abbruch der Suche.
- Von diesen ca. 40.000 Wörtern möchte ich maximal 1.000 wirkliche Schlagwörter in die Vorschlags-Liste (dem Glosar) einpflegen, ergänzt mit fachlich allgemein gebräuchlichen Synonymen.
- Das Ziel ist, wie ganz oben bereits formuliert, eine übersichtliche handliche Unterstützung des Besuchers beim Suchen in komplexen technischen Umfeldern.
- Der Einfluß auf Suchmaschinen oder SEO Ideen ist hierbei irrelevant.
.
.
- Die mnogsearch Sourcen müssten analysiert und ergänzt werden. Diese Suchmaschine wird offensichtlich nicht mehr gepflegt. Die Macher (in Russland) haben sich angeblich verkracht.
Es müssen 2 Stoplisten und eine Synonymliste von Hand gepflegt werden:
- Die Stoplist(1) für die allgemeine Suche (etwa verbleibende 40.000 Ergebnisse)
- die Stoplist(2) für das Glossar (etwa verbleibende 1.000 Ergebnisse)
- die Synonymliste für das Glossar (zur Zeit unbekannte Anzahl von Einträgen)
- Die Verkettung der Sort- und Prüfprozeduren muss protokolliert werden, weil alles im Hintergund auf dem Server laufen soll.
.
Die automatische Verschlagwortung nennt sich zwar so, ist aber für mein (unser) Problem nicht zielführend. In der Schlagwort-Vorschlagliste sollen die "themenspezifischen" Schlagwörter vorgeschlagen werden. Das hat weder etwas mit Gruppen oder Usern oder Rechten zu tun, es sind unsere selektierten ganz speziellen Fachbegriffe. Zum Beispiel ist das Wort "Löschen" oder "Delete" viel zu allgemein, um in einer "Typo3-Hilfe" Vorschlags-Liste auftauchen zu dürfen.
.
Auch das Erstellen von Synonymen ist überhaupt nicht trivial. (Ich meine also nicht die allgemeine deutsche Sprache, sondern eingegrenzte Inhalte von Fachpublikationen).
Nach meinen bisherigen Gedanken wäre eine Minidatenbank mit vorerst 2 Tabellen und einer "n zu m" Relation sehr gut geeignet, die aus dem Content ermittelten (Methode siehe oben) Ur-Schlagwörter in die n-Tabelle einzufüttern und dann alle bezogenen Begriffe in die m-Tabelle zu ergänzen.
Wenn das Tool dann eine Minioberfläche bekäme, könnte man da sogar die diversen Sprachen (also die Übersetzungen der Begriffe) mit unterbringen. Das dort auch inverse Relationen möglich wären, wie zum Beispiel:
Suche nach :
"Glossar", Anzeige der Synonyme und bezogenen Schlagwörter wie
glossary, schlagwort. suchwort, schlagworterstellung, ............
Und dann natürlich invers:
Suche nach :
Schlagwort mit Anzeige von glossar, glossary, usw...
.
Und wenn ja, wo (ausser google und ebay) ?
.
